


차세대 개발 경험 : 현대적 앱 개발을 다시 생각한다(기조연설)ServerlessAWS SAM(Serverless Application Model)DEMO 1. Amazon Bedrock - AI APP GenerateDEMO 2. Serverless Container느낀점어쩌다 AWS 인프라 구축 - 신규 서비스 개발을 위한 설계 고민들배경준비네트워크 기반 구성서비스 선택 배포 환경 구성Terraform (IaC)느낀 점카오스 엔지니어링과 AWS Fault Injection Simulator목표 Netflix문제해결방안카오스 엔지니어링안정상태 정의 장애 시나리오 선택가설 수립 실험검증 및 결과 확인왜 어려운가AWS FIS(Fault Injection Simulation)장점구성요소실 서비스 예시 ArchitectureArgoCD와 GitOps를 인터넷 없는 환경에서 구축하기아젠다해결해야할 문제 해결 방안해결 과정마무리느낀점클라우드 트래픽과 오토스케일링 다이나믹 컨트롤Agenda트래픽과 리소스 조절의 목표AWS 트래픽, 리소스 조절 대응AWS의 함수가 Traffic Surge를 만난다면?Traffic Surge의 대책SLOs와 Auto Scaling 간의 간극트래픽과 스케일링 통합적 관리MSA Scaling 1MSA Scaling 2AWS LambdaAWS WAFSevice MeshTime-based Scaling추천 도구 결론전체 세션 느낀점
차세대 개발 경험 : 현대적 앱 개발을 다시 생각한다(기조연설)
- Donnie Prakoso (GitHub : Donnieprakoso)
- Derek Bingham (LinkedIn : derekwbingham)

- 한국의 개발자는 대부분 Java..
Serverless
- AWS Lambda
- 서버리스
펑션 - 이벤트 중심으로 동작
- 비즈니스 로직과 같은 작은 기능
단기실행 및 주문 방식
- AWS Fargate
- 서버리스
컨테이너 - 유연하게 구동 가능
- 더 큰 규모의 어플리케이션
장기실행 및 지속적 사용 방식
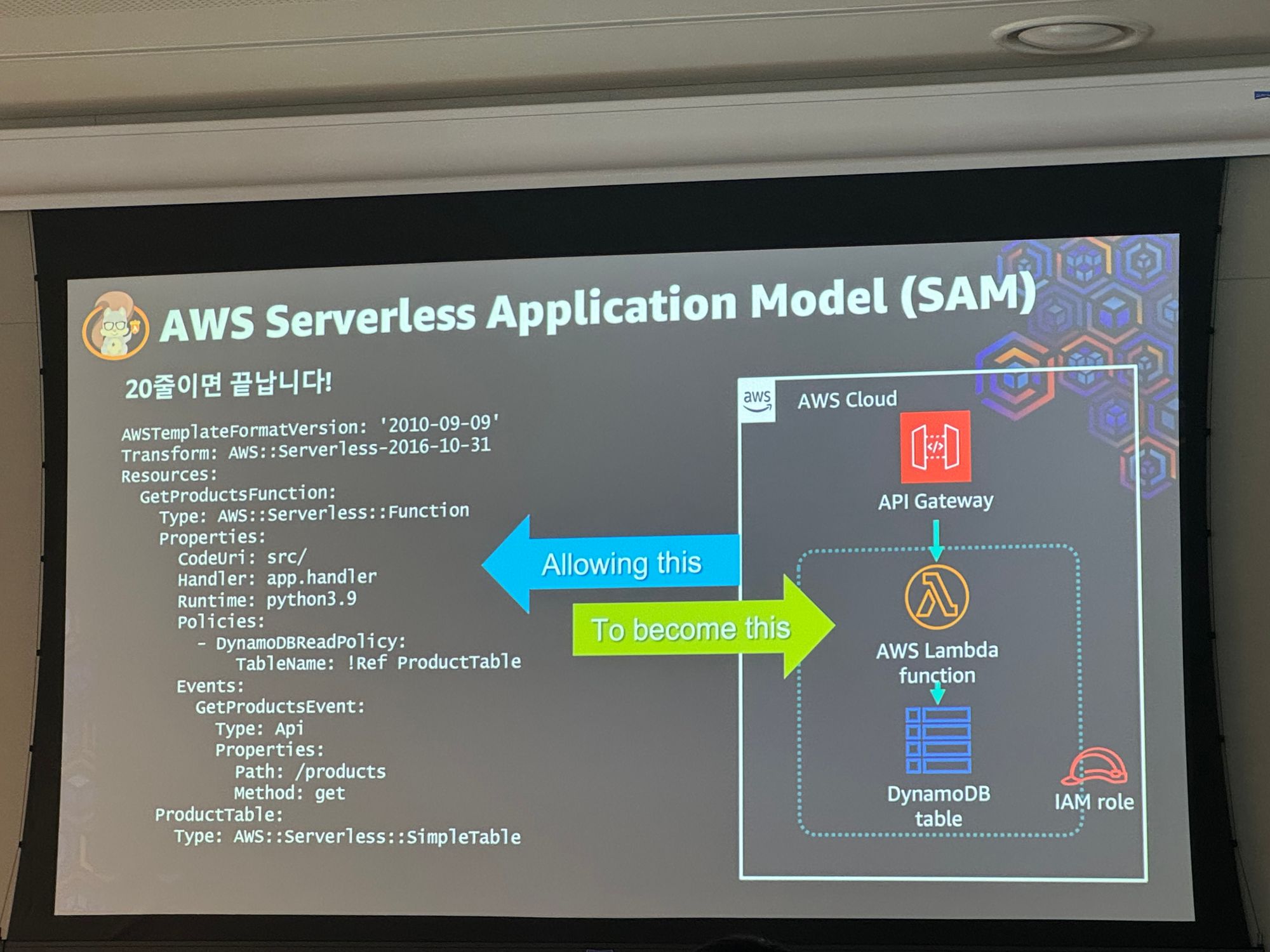
AWS SAM(Serverless Application Model)
AI가 인간을 대체할 수 없지만 AI가 있는 인간이 AI가 없는 인간을 대체할 것이다.
Amazon BedrockAPI를 통해 여러 파운데이션 모델에 접근해서 데이터를 제공 받을 수 있음
Amazon CodeWhisperer15개의 언어를 지원하여 코드 자동 추천 도구
DEMO 1. Amazon Bedrock - AI APP Generate
- 플레이그라운드를 통해서 쉽게 파운데이션과 모델을 선택해서 테스트 해볼 수 있음
- GPT 4.0 보다는 좀… 떨어지는 듯함
AWS Application Composer를 통해 손쉽게 람다 + s3 등 구성 가능
- 만들어진 Template.yaml 파일과
sam툴을 사용하여 구성을 deploy 할 수 있음
- AWS CDK(Cloud Development Kit)을 통해서도 구성 가능
DEMO 2. Serverless Container
- AWS Fargate (ECS, EKS을 손 쉽게 구성해 줌)
- AWS Copilot을 통해 손 쉽게 구성 가능하며 아래 단계를 모두 커버 가능함
- Deploy
- Check
- Integration
- Testing
- Release
- Etc…
- Resume Reading Easier Application Deploy Example
- Copilot을 통해서 서비스, 어플리케이션 관리 가능
- 손쉽게 AI 서비스를 연동해서 이력서를 요약해주는 서비스 구현 가능
느낀점
Bedrock 서비스를 통해서 손 쉽게 AI 어플리케이션을 만들 수 있고 개발을 잘 알지 못하는 사람들도 손쉽게 PoC(Proof-of-Concept) 서비스를 만들 수 있을 것 같다. 하지만 Bedrock에서 지원하는 파운데이션 모델들에 대한 성능은 아직 좋은 것 같진 않다. GPT 처럼 업데이트를 해가면서 더욱 좋은 성능을 내게 된다면 정말 좋은 AI 서비스가 되지 않을까 생각이 든다.어쩌다 AWS 인프라 구축 - 신규 서비스 개발을 위한 설계 고민들
- 안정수 (카카오)
배경
- 레거시 개발에 지쳐 새롭게 시작할 수 있는 프로젝트를 찾아 AWS 인프라 구축을 해보게 되었음
- 마음대로 = 책임🔺
- 업무 요구사항
- 기한 4개월, 제품 2개 개발
- 글로벌 타겟 (해외 Region)
- 하이브리드 (Private + AWS 연결을 어떻게 ?)
- 보안 가이드 준수
준비
- 네트워크 기반 구성
- 서비스 선택
- 배포환경 구성
- 모니터링
네트워크 기반 구성
- VPC 설계 진행
- 필요한 IP 계산
- 사내 네트워크 연결 고려
- 다른 팀과의 VPC 대역과 겹치지 않아야함
- DEV / PROD를 구분해서 설계
- EKS를 사용한다면 2배 이상의 대역을 부여해야함
EKS는 버전 업 하기 힘들기에 블루/그린 배포를 위해서 2배의 대역을 부여하는 것이 좋음
→ 블루/그린 배포를 하기 위해서는 2배만큼의 컴퓨팅 파워가 필요하기 때문
- Subnet 구성
- 역할에 따라서 구분해 구성
- NAT (Public)
- EKS Worker
- DataBase
- VPC Endpoint
→ Security 구성을 세분화 하기 위해서 구성
- AZ
- AZ를 많이 쓰면 비용 증가
- 2개 vs 3개 ?
- Aurora를 사용하려면 3개 이상의 AZ 세팅 필요
- 하지만 비용적 측면을 고려해 2개를 쓸 수 있으나 추천 x
서비스 선택
- Computing - EKS
- 세팅하기 위해서 생각보다 많이 시간이 듦
- 다시 한다면 흠… 안쓸듯
- 노드 그룹 선택 방식 3가지
- Managed
- Pod에 IP 할당 시 VPC 대역의 IP를 할당 받아서 사용함
- 하나의 작업 노드가 여러개의 IP를 점유할 수 있음
- 노드 사이즈에 따라 연결할 수 있는 ENI(Elastic Network Interface) 수가 차이 있음
- 노드 사이즈에 따라 대역폭도 차이가 있음
- AWS Fargate
- vcpu, memory 조합이 정해져 있다
- 노드를 관리해야 하는 필요가 있기에 적합 x
- Public Subnet 사용 불가, NLB 사용 불가
- 좋아 보이지만 사용하기 어려운 점이 있기 때문에 꼭 알고 써야함
- Self-Managed (거의 사용 x)
- OIDC(OpenID Connect)를 연결하는게 제일 어려움 (k8s RBAC)
- DB - RDS
- Aurora가 좋고 사내 DB조직에서 DB Mysql을 사용하라해서 그걸 씀
- Storage - S3 / CloudFront
- CDN으로 S3를 사용
- IA 기능 활성화
- Cache - Redis
- Push Integration - SQS, SNS
- SNS + Kinesis를 적용해서 구현 (기존 Kafka를 사용했던 경험을 살려 적용)
- 하지만 to much 방식이다
- 만약 다시한다면 SNS + SQS만 써서 구성할 것 같다 → kafka 연결 없이 SNS + SQS만 해도 Push 구성을 충분히 해낼 수 있다
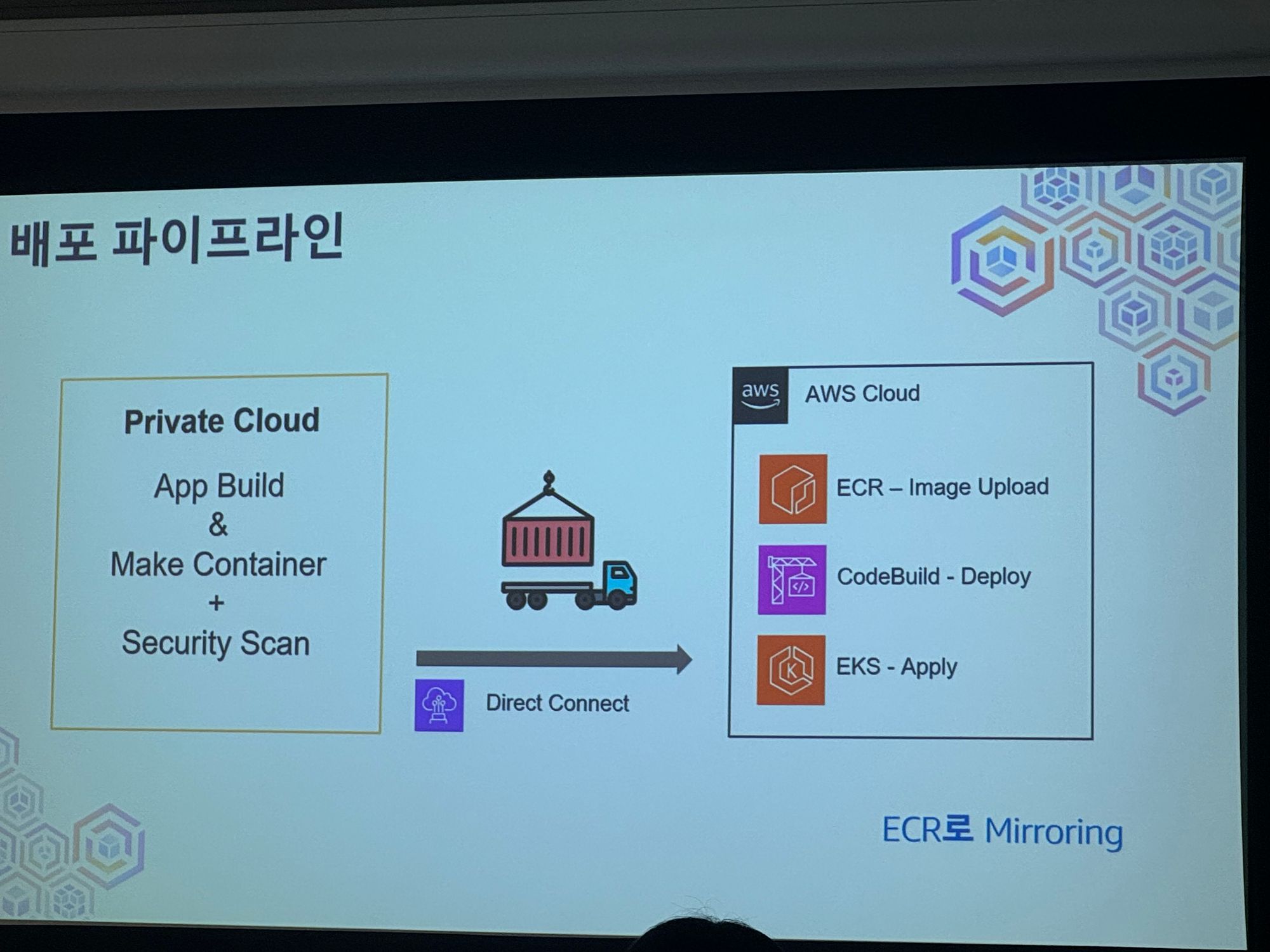
배포 환경 구성
- 수 많은 옵션이 있고 자체 Container Build 시스템이 있기 때문에 별도 환경 구성 x
Terraform (IaC)
- 기본은 진짜 기본 값 Production 레벨에 맞춰서 잘 설계 해야 함
느낀 점
- AWS 서비스는 다양하니 아는 만큼 활용할 수 있다
- 한 번에 모든 infra를 바꾸려하지 말고 조금씩 구성해가면서 바꿔가면서 적용
- IaC를 통해서 언제든지 새롭게 만들고 테스트하기
- 기본 값은 진짜 기본이다. Production은 반드시 그에 맞는 설정 값 적용 필요
- 잘 모르는 부분은 그냥 넘기지 말고
RTFM하기
RTFM(Read The Fuxxing Manual)은 제발 매뉴얼을 좀 읽으라는 의미, 한국인 답게 매뉴얼을 안 읽는 경우가 많은데 매뉴얼을 줄땐 이유가 있어 주는거니 꼭 필독 !
카오스 엔지니어링과 AWS Fault Injection Simulator
- 윤정원 AUSG (eatingcookieman@gmail.com)
목표
- 카오스 엔지니어링의 이점
- 카오스 엔지니어링을 잘하는 법
- 카오스 엔지니어링을 쉽게하는 법
Netflix
- MSA
- Chaos Engineering
문제
- 2008년에 DB 장애로 인해 3일 동안 멈춤
- SPOF(단일 장애 지점)을 벗어나기 위해 필요성을 느낌
해결방안
- Chaos Monkey
- 인스턴스 또는 컨테이너를 무작위 종료 시켜 테스팅 하는 툴 (오픈소스)
카오스 엔지니어링
- Muscle memory
- 머리가 아닌 몸이 기억하는 대처
- 안정상태 정의
안정상태 정의
- 측정 가능한 지표
- 처리량, 에러율, p95/p99 Latency
- 비즈니스 관점 지표
- 시스템이 정상적으로 작동하는지 검증
- 실제 서비스 지표
- 아마존의
OPS(Order Per Second) - 넷플릭스의
SPS(stream Start Per Second)
장애 시나리오 선택
- 과거 발생한 모든 장애
- 작은 것 부터
- 리소스 레벨
- CPU, memory, I/O
- Disk Space
- Application APIs
가설 수립
- 특정 시스템, 특정 장애, 특정 동작, 안정 상태
- 귀무 가설(Null Hypothesis) 형태를 사용
- 귀무 가설은 “틀렸다” 라는 것을 확인
- 참이 아님을 증명하는 것이 참을 증명하는 것 보다 더 쉽기 때문
실험
- 실제 환경에 가깝게 구성
- 영향 범위 축소
- 긴급 중단 계획 수립 필수
- 롤백 계획
- 조직에 공지
- 실험 영향도가 수립 되어야 함
검증 및 결과 확인
- 실험군과 대조군 모두 안정 상태인지 확인
- 안정 상태 외 다양한 항목들 확인
- 장애 감지 시간
- 전파 시간
- 시점
- Self-Healing 시간
- 부분 복구 시간
- 종료 까지 걸린 시간
왜 어려운가
- 실험을 위해 스크립트가 작성 되어야한다
- 안전하게 실험하기 힘들다
- 현실 사건을 재현하기 힘들다
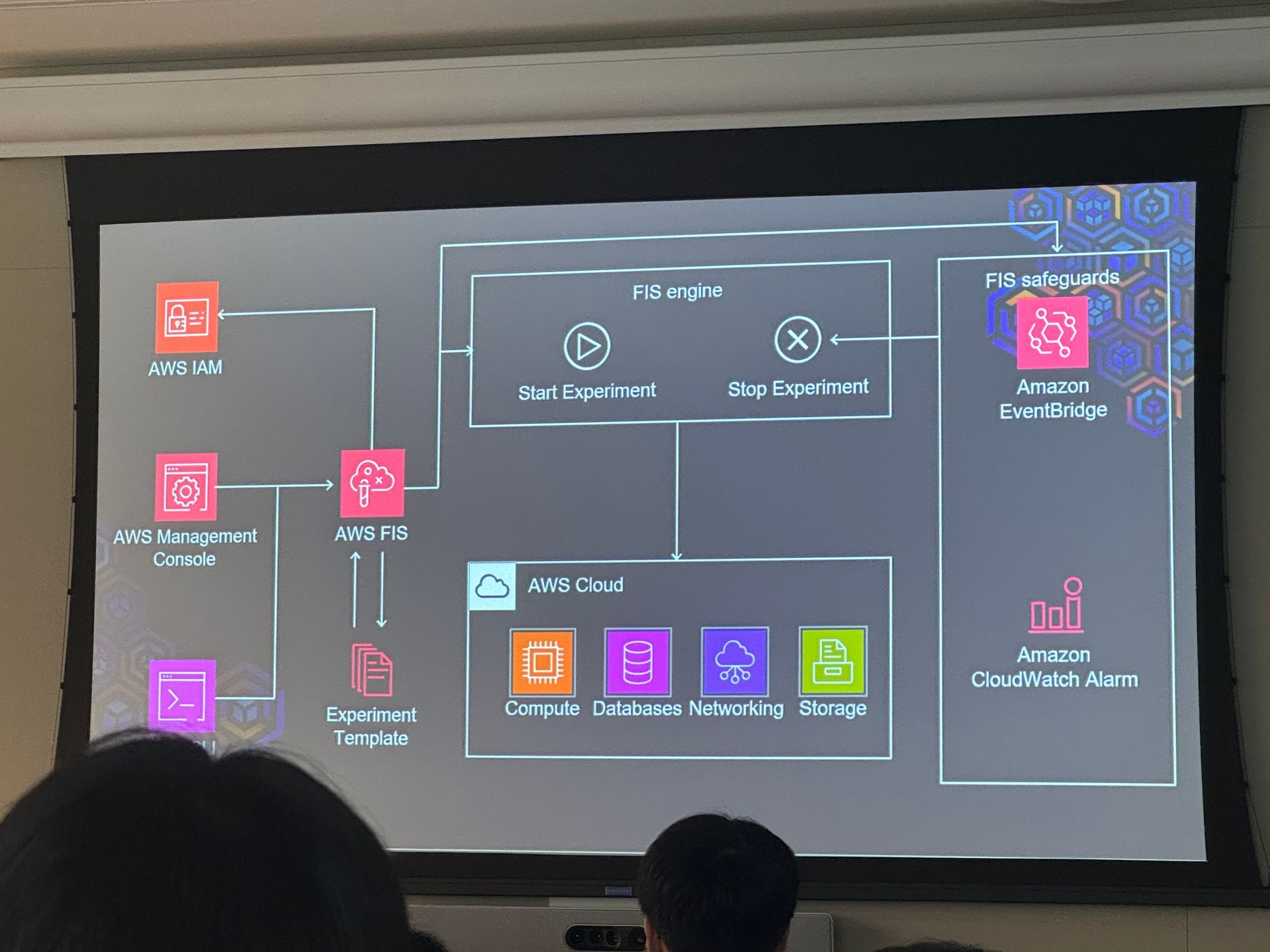
AWS FIS(Fault Injection Simulation)
- 완전 관리형 카오스 엔지니어링 툴
- 다양한 서비스 테스트 가능
- 호스트 ~ API 에러등 다양한 기능 제공
- 중단 조건, 롤백 기능 지원
- 실험 템플릿 제공
- 정애 주입 시간만큼 비용 내는 구조 (분당 $0.1)
장점
- 손쉽게 장애 주입 가능
- 스크립트 만들기, 에이전트 설치 필요 x
- Json/ yaml을 통해 템플릿 사용 가능
- 실제 장애 사례 기반 실험 가능
- 장애 이벤트 순서 또는 병렬 적으로 진행 가능
- 안전하게 실험 가능
- 자동 중단 조건 설정 가능
- 롤백 기능 기본 제공
- CloudWatch와 통합 가능
- 세분화 된 IAM 제어 가능
구성요소
- Targets
- 장애 주입 및 AWS 리소스
- 각종 서비스에 대한 유형 선택 가능
- Subnet, VPC, AZ 등 선택 가능
- 선택모드 (ALL, COUNT, PERCENT)가 있음
- Actions
- 어떤 Target에게 어떤 장애를 주입할 것인지 설정
- 여러 작업을 동시 실행 및 순차 작업 진행 가능
- 다양한 장애 지원
- AWS SSM Document 활용 가능
- ChaosMesh 및 Litmus 활용 가능
- Experiment templates
- 자동 중단 조건 알람 가능
- 수동 중단 기능도 제공
- Event Bridge를 통해서 다른 모니터링 서비스와 연동 가능
- Experiments
- 실험 내역 확인 가능
실 서비스 예시 Architecture
ArgoCD와 GitOps를 인터넷 없는 환경에서 구축하기
- 정영진 (LG U+)
아젠다
- 해결 문제
- 해결 방안
- 해결 과정
- 마무리
해결해야할 문제
- 기술 부채 (Technical debt quadrants)
- 유지 관리
- 안정성
- 기술 제품
- 개발자 효율성
- 보안
- 의사결정
- 문제 정의
- 여러 계정을 사용한 EKS 관리
- Non-Immutable 인프라 구축 및 배포
- 히스토리 추적
해결 방안
- Proxy Server를 이용한 EKS 외부망 통신

- GitOps와 ArgoCD
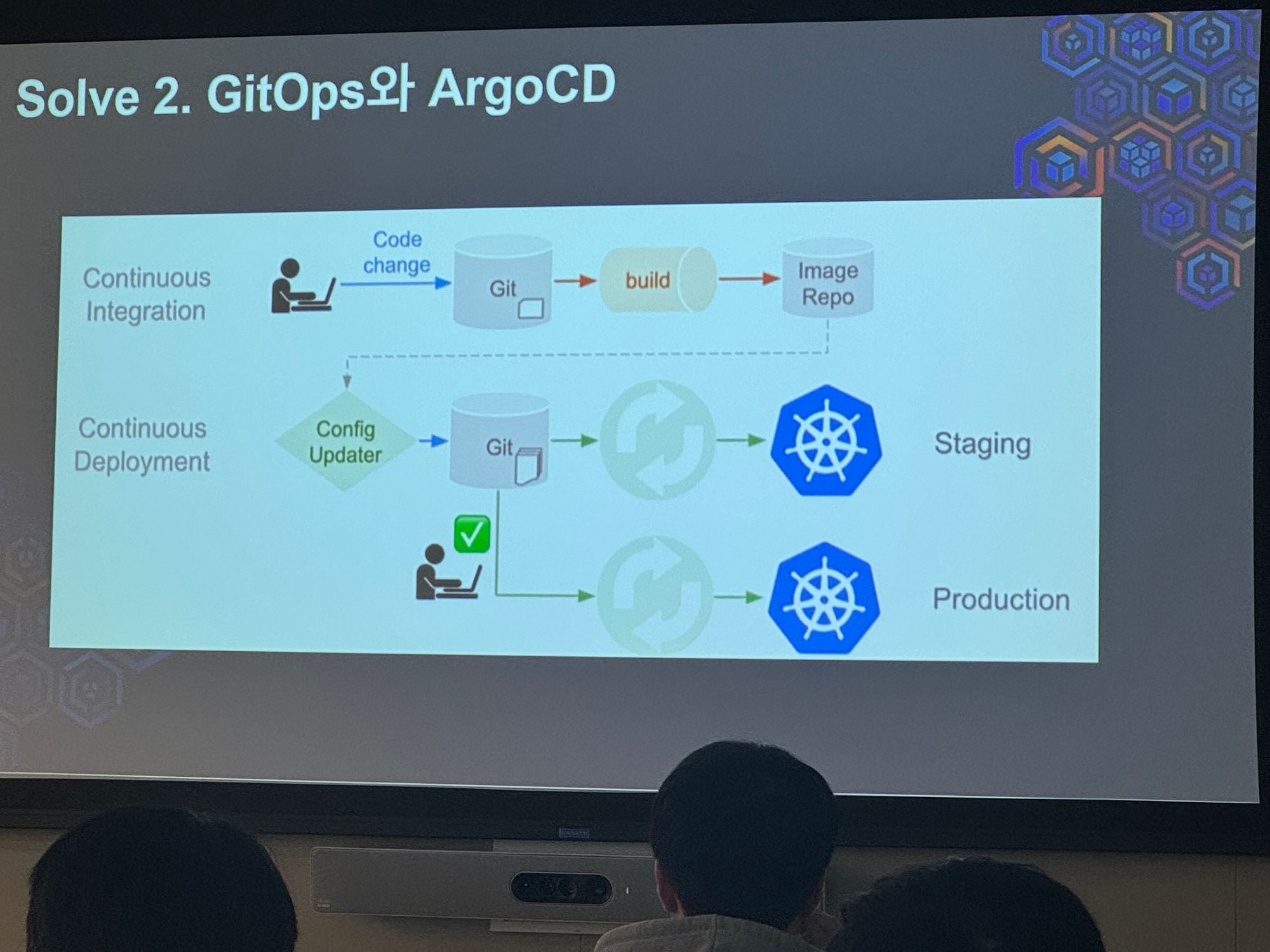
- RBAC을 통한 ArgoCD (using Okta)
해결 과정
- Trraform Import
- Centralize EKS Cluster 구축
- Centralize ArgoCD 리소스 배포 (Kustomize 사용)
- VPC Peering
- Destination EKS Cluster 생성
- Centralize ArgoCD 배포 권한 설정 추가 (Parameter Store)
- Destination Cluster 확인
- 리소스 배포
마무리
- 편안한 관리 및 가시적인 배포가 가능해짐
- GitOps 모델 성숙도 2~3레벨 정도 구성 → 최종 목표는 완벽한 3레벨 GitOps 구축
- 처음부터 IaC를 하지 않은 이유 시간이 없어서… 어려워서 ..?
- IGW와 NAT를 못 만들게 하는게 과연 맞을까 Proxy Server를 타게 하면 인터넷이 되는데…
- 배포 히스토리 관리는 어떻게 ? Jenkins를 활용하면 가능하지 않을까 ?
느낀점
역시 대기업 답게 큰 규모의 CI/CD 환경을 만들어내는 것을 보니 이런 대규모의 CI/CD 구축 환경은 스타트업과는 맞지 않는 것으로 생각 된다. 만약 서비스 규모가 작다면 이를 축소해서 CI/CD 구성 비용을 낮추는 것이 더 좋은 것 같다.
클라우드 트래픽과 오토스케일링 다이나믹 컨트롤
- 김환수 (DoE of STCLab)
Agenda
- 트래픽과 리소스 조절의 목표
- AWS 트래픽, 리소스 조절 대응
- 스케일링 전략
- MSA
- AWS Lambda
- AWS WAF
- Service Mesh (AWS EKS)
트래픽과 리소스 조절의 목표
- SLOs (Service-Level Objectives)를 정하는게 중요
- 조절(트래픽, 리소스) = 시스템 장애 낮춤, 고객 경험 증가, 비용 낮춤
AWS 트래픽, 리소스 조절 대응
여러 서비스들을 통해서 조절이 가능함
- ELB
- AAG
- AD
- EC2 Auto Scaling
- ECS
- EKS
AWS의 함수가 Traffic Surge를 만난다면?
- 각종 서비스들이 언제 scale-up or out 되는지 타이밍이 중요
- %로 Auto Scaling 설정을 하면 계속 scale-out 하게 되어버리는 문제
Traffic Surge의 대책
- 고객 경험이 중요하다면 → Overprovisioning, 일단 터지지 않게 늘려서 설정
- 특정 이벤트 할때 늘리기 → 클라우드 엔지니어들의 비용 소모
- 비용 절감이 제일 중요하다면 → 어떻게든 적정 CPU Utilization 값을 찾아서 적용 필요
SLOs와 Auto Scaling 간의 간극
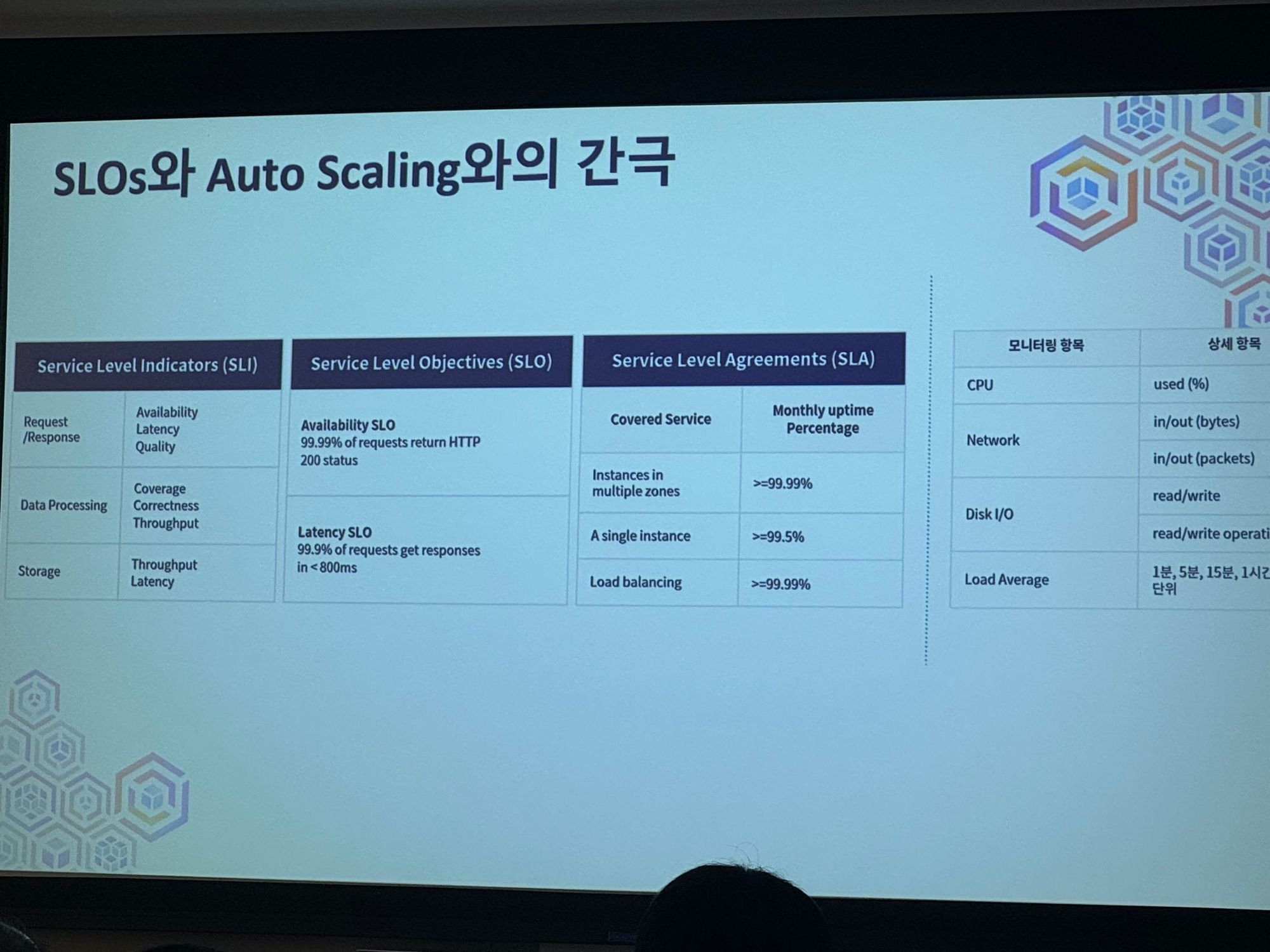
→ AWS가 모든걸 다 해주지 안흔ㄴ다
트래픽과 스케일링을 위한 전략적 관리가 필요함
트래픽과 스케일링 통합적 관리
- KEDA (K8s Event-driven Autoscaling)
- Wave Autoscale 프로젝트를 진행 중
MSA Scaling 1
Responsive Scaling with Dependent Services
→ 단순하게 Dependent 한 서비스들의 모든 사용량을 스케일링 (kiali)
Kiali를 통해서 스케일링에 대한 상태 확인이 가능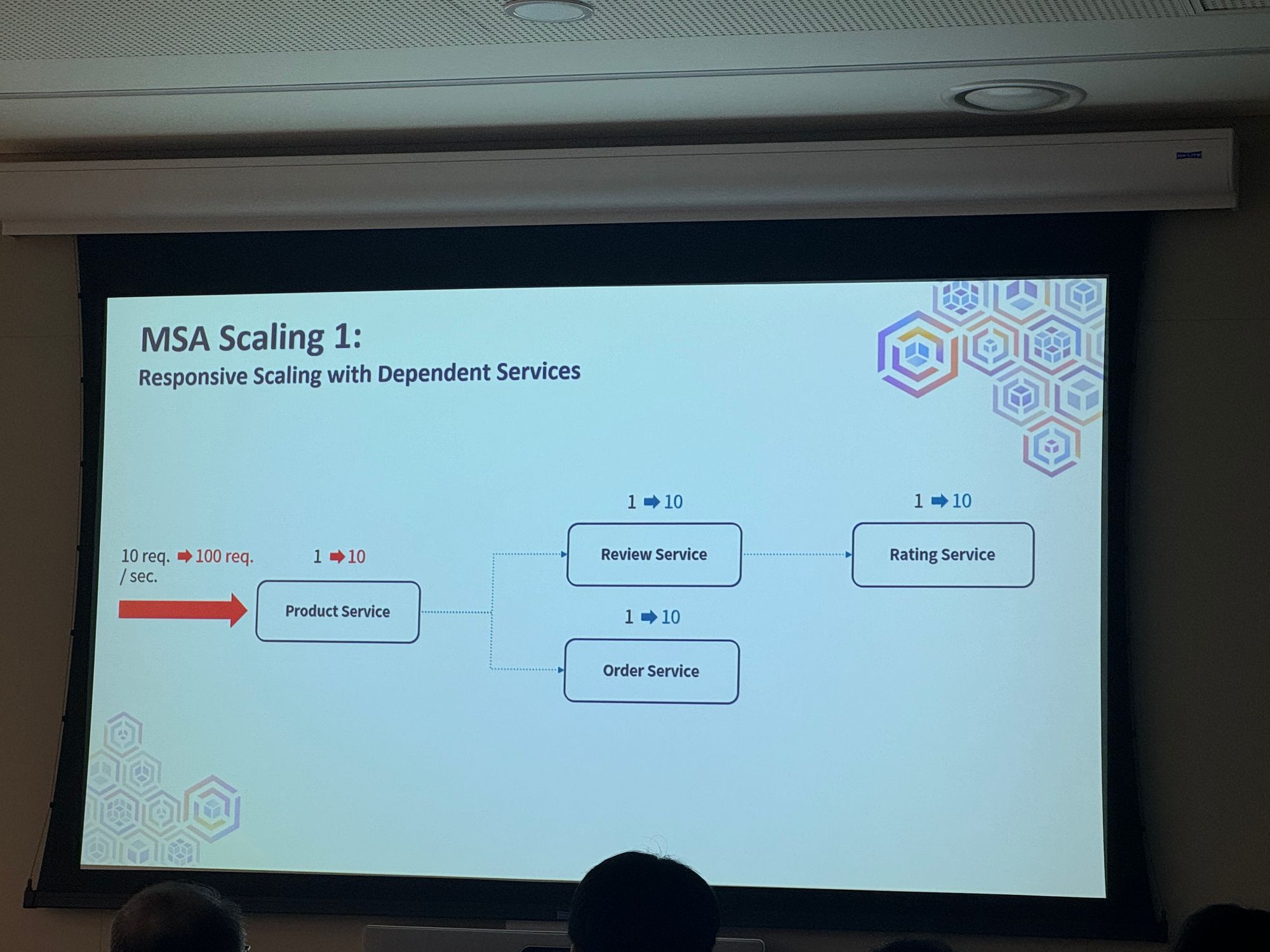
MSA Scaling 2
Responsive Scaling with Business Process
→ 비즈니스 프로세스의 지표를 통해서 스케일 작업 진행, 기능별 비즈니스 지표를 참조
Surffy를 통해 기능별 트래픽 모니터링해서 확인가능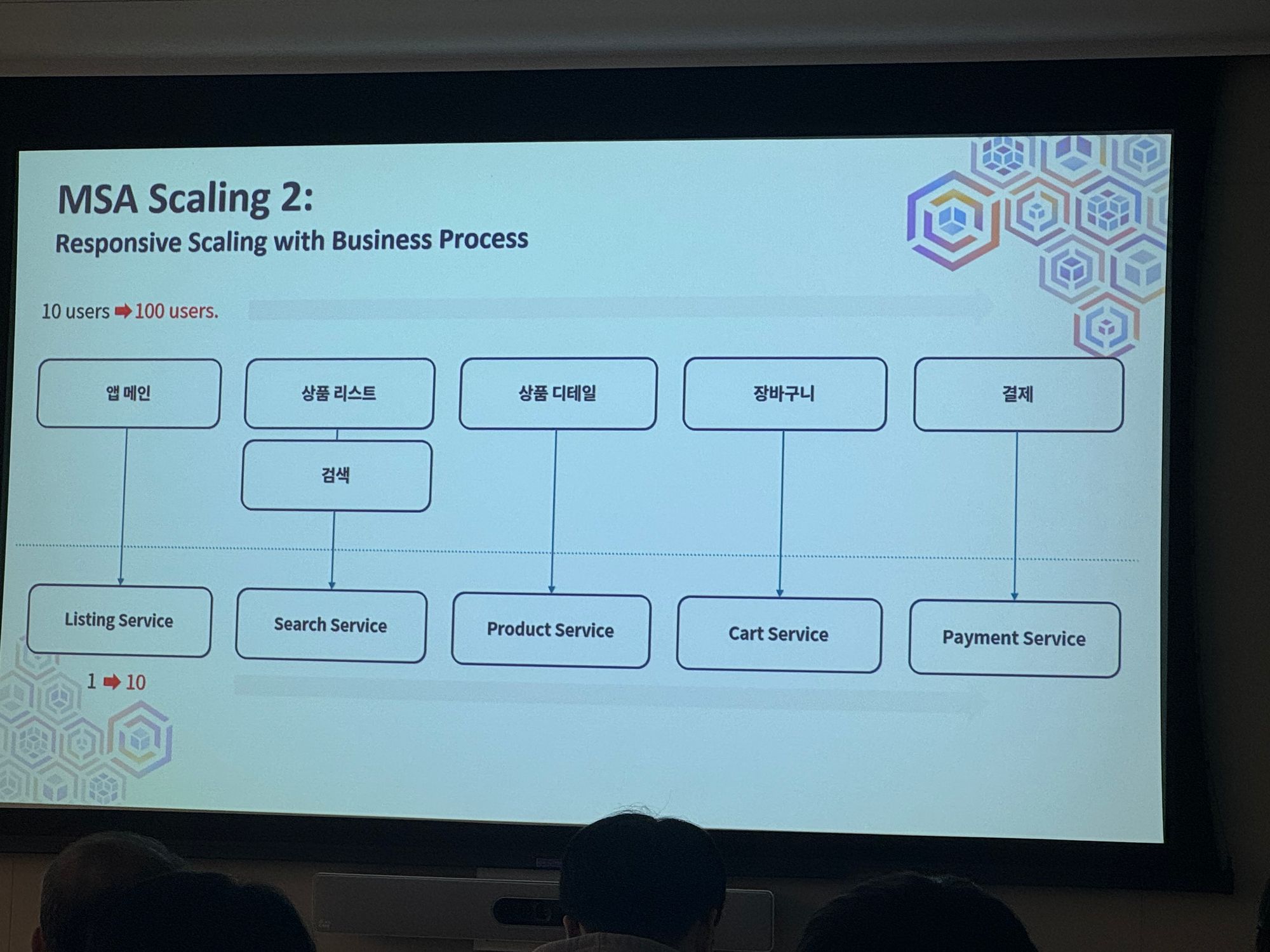
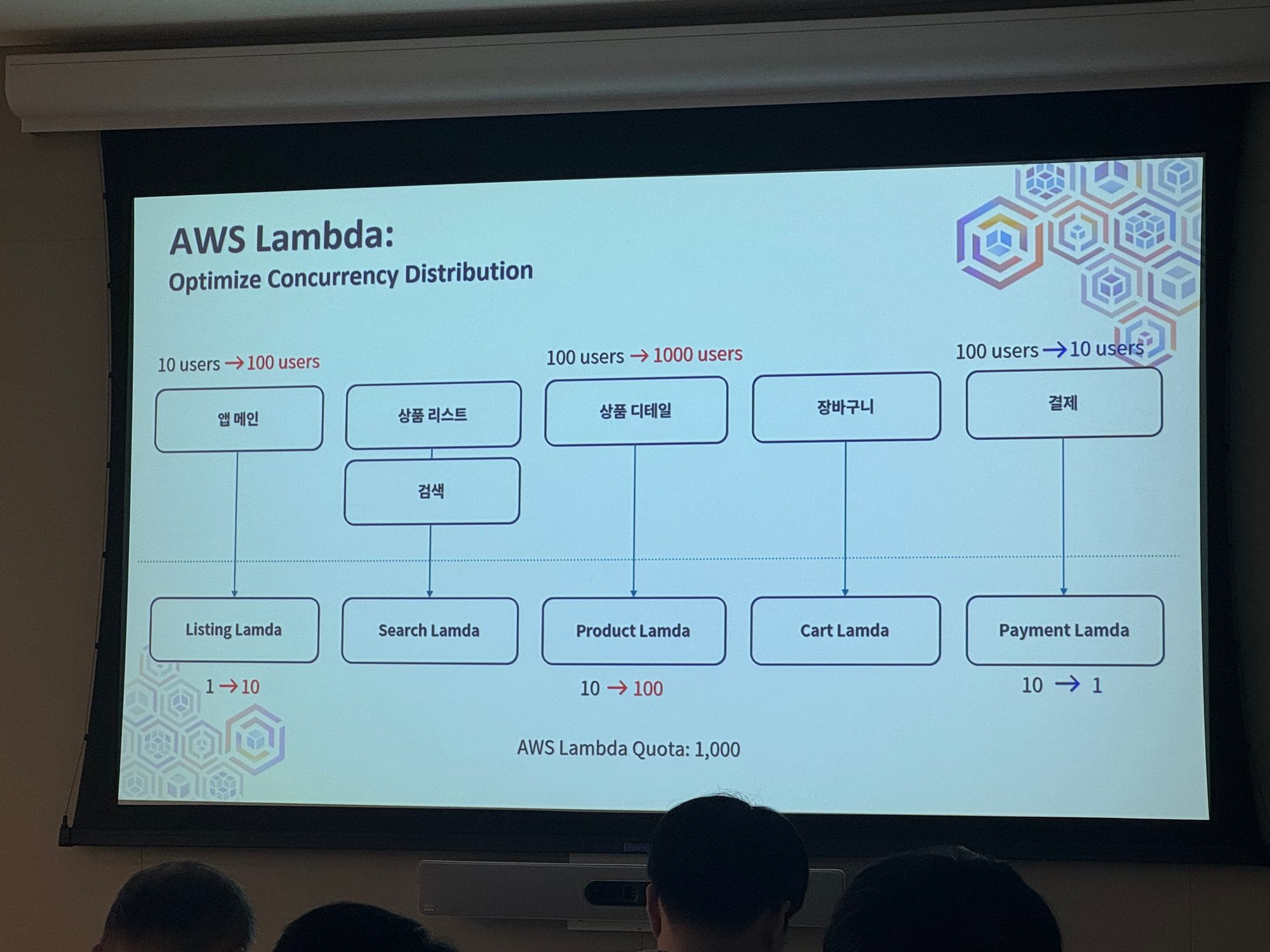
AWS Lambda
Optimize Concurrency Distribution
→ 트래픽에 따라서 Lambda의 Quota 값을 수정해서 스케일링 가능
AWS WAF
Traffic Handling During Database Throttling
→ AWS의 WAF를 통해서 DB 접근의 쓰로틀링을 걸어 제한을 둘 수 있음

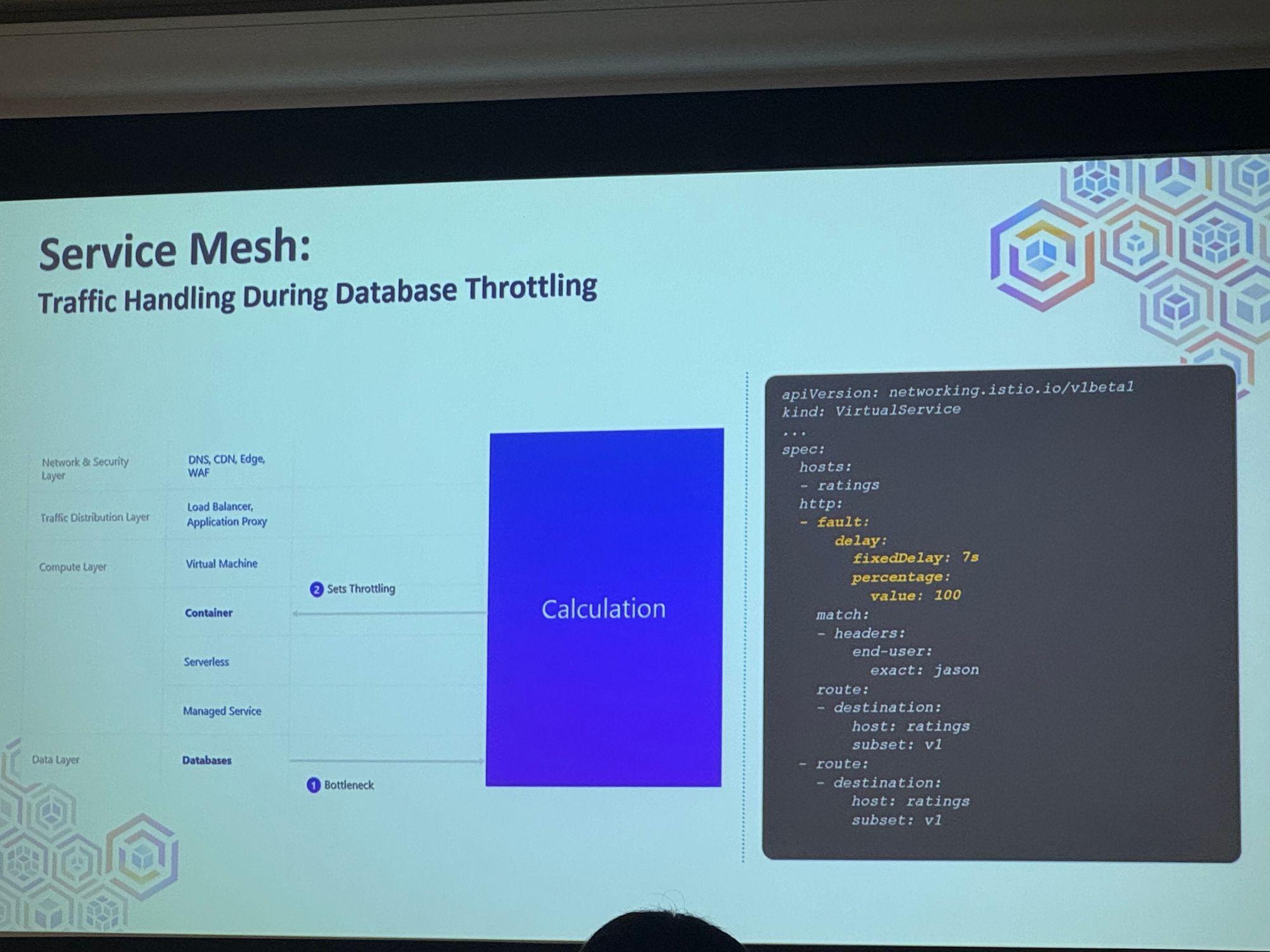
Sevice Mesh
Traffic Handling During Database Throttling
→ 트래픽에 따른 데이터베이스의 접근 딜레이 값을 설정
Time-based Scaling
시간을 기준으로 스케일링하는 방법이 있음
Ex) 한국 기준이라면 점심시간에는 스케일업하고 새벽시간엔 다운하는 방안
추천 도구
Open-source Traffic & Scaling Automation Tool
Wave Autoscale
- 각종 서비스 연동 쉬움
- Telegraf, Vector와 같은 오픈소스 메트릭스 를 이용한 다양한 지표 트리거 연동 가능
결론
- 인프라 구축시에는 항상 상황에 맞는 SLOs를 구성
- 탄탄한 observability 설계 및 구축 필요
- 비즈니스 컨텍스트, 컴포넌트 컨텍스트의 의존성 활용 하여 구성
- 최대한 스케일링의 자동화는 할 수록 좋다
전체 세션 느낀점
대체로 AWS에 타깃이 맞춰져있다 보니 새로운 AWS 서비스들에 대해서 알게 되었다. 이제는 개발자가 아니더라도 쉽게 블록을 끼워 맞추듯이 개발을 할 수도 있다는 점이 크게 와닿았고 강의 중 이야기되었던 것 중 하나인 “AI가 인간을 지배하는 것이 아니라 AI를 활용하는 인간이 쓰지 않는 인간들을 지배하게 될 것이다”라는 문구가 크게 와닿았다.
최근 Chat GPT 4.0을 결제해서 사용하고 있는데, 정말 경이로운 수준의 Indexing 능력을 가지고 있었다. 하지만 이러한 Chat GPT도 사용자가 어떻게 질문하느냐에 따라서 답변이 달라질 수 있다. 앞으로 미래를 준비하기 위해서는 알고 있는 서비스가 많고 그걸 얼마나 활용할 수 있는지가 그 사람의 능력이 되지 않을까라는 생각이 들었다.